在这个AI大爆发的时代,各种智能工具如雨后春笋般涌现,大语言模型的能力也在不断刷新我们的认知。随便拉出一个AI模型,似乎都能轻松应对各种复杂的翻译任务,让人不禁感叹:这哪里是翻译,简直就是语言大师!
然而,当我们沉浸在AI翻译的便利中时,一个现实问题悄然浮现:面对如潮水般涌来的前沿论文和技术资讯,我们的翻译需求也在与日俱增。传统的翻译工具此时就显得有些力不从心了——翻译质量忽高忽低,速度慢得让人想打瞌睡,费用高得让钱包直叫唤,更别提那些不通人情的直译,经常闹出笑话。
大语言模型就像翻译界的超级英雄,凭借强大的学习能力和适应性,彻底改变了翻译游戏规则。它们在翻译质量、效率、上下文理解和多语言支持方面表现惊人,不仅能准确把握原文精髓,还能用地道表达呈现,仿佛每种语言都是它们的母语。
正是在这样的背景下,上海人工智能实验室(Shanghai AI Lab)的LLaMAX横空出世。通过长达3.5万小时的A100 GPU训练(没错,你没看错,是3.5万小时!),LLaMAX掌握了100多种语言的翻译能力。这就像是给AI装上了一个超级语言芯片,让它能够在100多种语言翻译中应对自如。
LLaMAX的出现不仅是技术突破,更是跨语言交流的革命,从非洲的斯瓦希里语到南美的克丘亚语,它都能应对自如。无论是商业往来还是学术研究,语言障碍将不再是绊脚石。
论文标题:
LLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
论文链接:
https://arxiv.org/pdf/2407.05975

多语言能力,大模型的新挑战
在人工智能领域快速发展的今天,大语言模型(LLMs)展现出了令人瞩目的能力,在各种自然语言处理任务中表现***。然而,这些模型在处理非英语语言时往往面临着严峻的挑战,特别是在低资源语言的翻译任务上表现不佳。这一问题的根源在于大多数LLMs主要基于英语数据进行预训练,导致它们在处理其他语言时存在明显的性能差距。
上海人工智能实验室的研究团队敏锐地察觉到了这一问题的重要性。他们认识到要真正实现人工智能技术的全球化应用,必须突破语言的藩篱,让大模型能够流畅地处理多种语言。为此,他们提出了LLaMAX项目,旨在通过持续预训练的方法,显著提升LLaMA系列模型的多语言能力。

研究团队的目标是让LLaMAX能够掌握100多种语言的翻译能力。如下图所示,传统的大语言模型在处理不同语言时存在明显的性能差异。特别是在处理阿拉伯语等非拉丁字母语言时,性能下降更为明显。LLaMAX项目正是要解决这一问题,实现各种语言之间的性能均衡。

此外,研究团队还注意到了现有开源多语言大模型的局限性。虽然一些模型如PolyLM、Yayi2等已经在多语言处理方面做出了努力,但它们的性能仍有较大提升空间。特别是在低资源语言的翻译任务上,这些模型的表现远远不能满足实际应用的需求。

LLaMAX项目的另一个重要目标是探索如何在提升多语言能力的同时,保持模型在英语任务上的***表现。这一点***关重要,因为许多现有的多语言模型在增强非英语能力时,往往会导致英语任务性能的下降。
总的来说,LLaMAX项目旨在通过创新的技术手段和大规模的训练资源,突破大语言模型在多语言处理方面的瓶颈。通过提升模型的多语言能力,LLaMAX有望为跨语言交流、多语言信息检索等领域带来革命性的变革,***终实现人工智能技术的普惠化和全球化。
持续预训练与关键技术创新
为实现LLaMAX的目标,研究团队采用了持续预训练(continual pre-training)方法,并在此基础上进行了一系列创新性的技术探索。这些核心方法和技术创新包括:
词表扩展策略优化
研究团队深入分析了词表扩展对模型性能的影响。随着新增词汇量的增加,模型在罗马尼亚语(ro)和孟加拉语(bn)上的翻译性能呈现下降趋势。特别是当新增词汇达到51200个时,spBLEU分数分别降***17.79和1.14,远低于原始词表的性能。
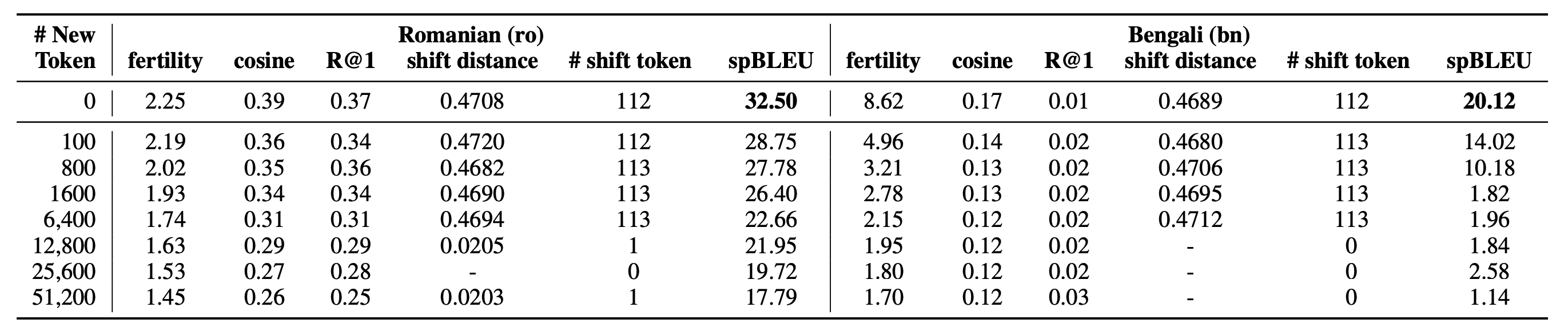
此外,团队利用KS-Lottery方法观察到新增词汇导致了原有词嵌入分布的显著偏移。如上表中的"shift distance"和"# shift token"列所示,过多的新词会改变模型的训练重点。
基于这些发现,研究团队决定保留LLaMA2的原始词表。这一策略不仅简化了训练过程,还有效保持了模型的性能稳定性。
数据增强技术创新
为解决低资源语言数据不足的问题,研究团队采用了基于字典的数据增强方法。
他们比较了MUSE和PanLex两种多语言字典的效果。字典中目标语言实体的数量与翻译性能呈现正相关。例如,在英语到泰语(en→th)的翻译中,PanLex字典由于包含更多泰语实体(297573 vs 21567),使得spBLEU得分从5.45提升到6.14。

研究团队还探索了单跳(1-hop)和双跳(2-hop)翻译在数据增强中的效果。单跳翻译通常优于双跳翻译,这可能是因为单跳翻译能更好地保持原始语义,减少错误累积。


平行语料处理策略优化
在处理平行语料时,研究团队提出了"connected-parallel"方法。这种方法将源语言和目标语言的句子对视为一个整体,而不是分别处理。实验结果表明,"connected-parallel"方法在各种翻译方向上都取得了显著的性能提升。例如,在ceb→en(宿务语到英语)的翻译中,spBLEU从23.19提升到27.06。

持续预训练框架设计
研究团队设计了一个高效的持续预训练框架,该框架包括动态数据采样、多语言混合训练等策略,以确保模型能均衡学习各种语言的特征。在训练过程中,团队使用了24台A100 80GB GPU,持续训练超过60天,累计训练时间达3.5万GPU小时。
训练数据的构建也是一个关键环节。团队收集了包括MC4、MADLAD-400和Lego-MT在内的多个数据集,覆盖了102种语言的单语和平行语料。

指令微调优化
为了进一步提升模型的实用性,研究团队在持续预训练后进行了指令微调。他们使用Alpaca数据集进行英语指令微调,同时探索了特定任务的多语言指令微调策略。这种策略显著提升了模型在多语言常识推理(X-CSQA)、自然语言推理(XNLI)和数学推理(MGSM)等任务上的性能。
多语言能力的评估与分析
研究团队还深入分析了模型的多语言表现。如图6所示,他们研究了词素化(fertility)与嵌入质量之间的关系,发现高词素化率可能导致较差的嵌入质量。这一发现为理解和改进模型的多语言能力提供了新的视角。

通过这些创新性的方法和技术,LLaMAX成功突破了传统大语言模型在多语言处理方面的瓶颈。研究团队不仅提升了模型的多语言翻译能力,还确保了模型在各种跨语言任务中的***表现,为大语言模型的多语言应用开辟了新的可能性。
实验结果:多语言能力的全面突破
LLaMAX模型在一系列严格的评测中展现出了***的多语言处理能力,证明了其作为一个强大的多语言基础模型的潜力。以下是主要实验结果的详细分析:
Flores-101基准测试
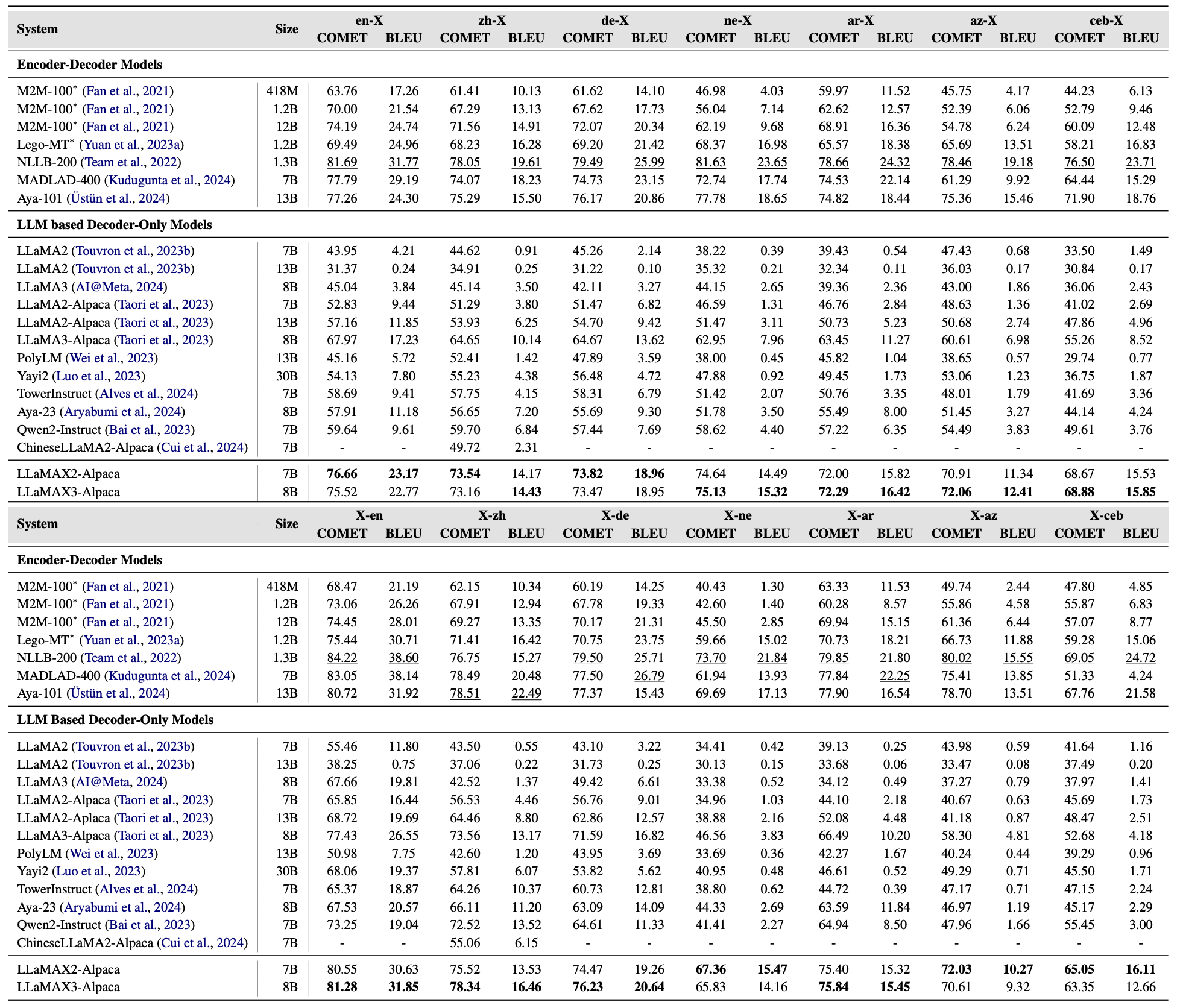
在Flores-101多语言翻译基准测试中,LLaMAX展现出了显著的性能优势。LLaMAX-Alpaca在各种语言对的翻译任务中均优于其他开源大语言模型。特别是在低资源语言的翻译任务中,LLaMAX的性能提升更为显著。例如,在尼泊尔语(ne)相关的翻译任务中,LLaMAX-Alpaca的COMET分数达到了74.64(en→ne)和67.36(ne→en),远超其他模型。
与专业翻译系统的比较
LLaMAX不仅在开源大语言模型中表现出色,还与专业的翻译系统展开了激烈竞争。如上表所示,LLaMAX-Alpaca的性能已经达到了专业翻译模型M2M-100-12B的水平,在某些语言对上甚***超越了后者。这一结果表明,通用大语言模型在多语言翻译任务上具有巨大潜力。
泛化能力评估
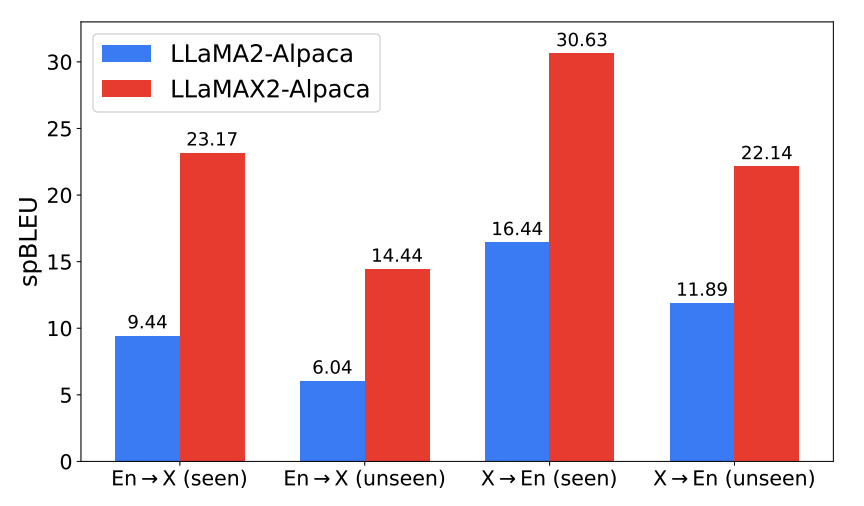
为了评估LLaMAX的泛化能力,研究团队在Flores-200数据集上进行了测试。即使对于训练中未见过的语言,LLaMAX仍然表现出色。在未见语言的翻译任务中,LLaMAX-Alpaca的spBLEU分数比LLaMA2-Alpaca高出8.4点(en→X)和10.25点(X→en),展示了强大的跨语言迁移能力。
多语言任务性能
除翻译任务外,LLaMAX在其他多语言任务上也表现优异。下图展示了LLaMAX在多语言常识推理(X-CSQA)、自然语言推理(XNLI)和数学推理(MGSM)等任务上的性能。在这些任务中,LLaMAX-Task(经过任务特定指令微调的版本)均优于LLaMA2-Task,证明了其作为多语言基础模型的优势。

基础能力保持
值得注意的是,LLaMAX在提升多语言能力的同时,并未牺牲模型的基础英语处理能力。LLaMAX-Alpaca在MMLU、BBH、NQ等英语基准测试中的表现与LLaMA2-Alpaca相当,有效避免了灾难性遗忘问题。

与GPT-4的对比
研究团队还将LLaMAX与GPT-4进行了对比。虽然在高资源语言(如英语、中文、德语)的翻译上LLaMAX略逊于GPT-4,但在低资源语言(如尼泊尔语、阿塞拜疆语、宿务语)的翻译任务上,LLaMAX展现出了与GPT-4不相上下甚***更优的性能。

多语言模型对比
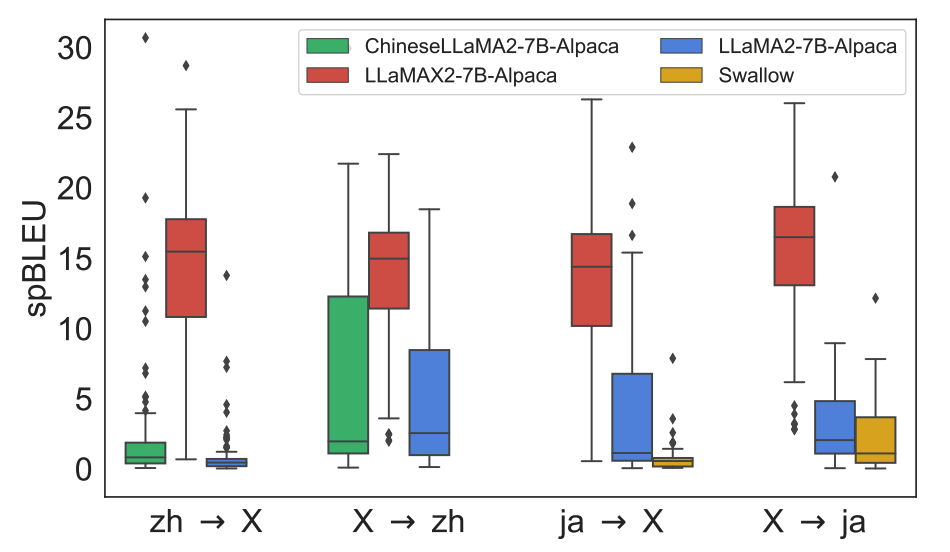
在与其他多语言模型的对比中,LLaMAX展现出了全面的优势。LLaMAX-Alpaca在中文和日语相关的翻译任务中均优于专门针对这些语言优化的模型(如ChineseLLaMA2-Alpaca和Swallow)。
研究团队还探讨了以英语为中心的翻译策略。通过将直接翻译(src→trg)转化为基于英语的两步翻译(src→en→trg),LLaMAX-Alpaca的性能得到了进一步提升。这一发现为多语言翻译系统的设计提供了新的思路。

综上所述,LLaMAX在多语言处理能力上取得了全面的突破。它不仅在翻译任务上表现出色,还在各种跨语言理解和生成任务中展现了强大的潜力。这些实验结果充分证明了LLaMAX作为一个真正的多语言大模型的价值,为未来的多语言AI应用奠定了基础。
总结与展望
LLaMAX的横空出世,就像是给大语言模型装上了语言百宝箱!经过3.5万小时的A100 GPU训练,这位AI语言大师不仅精通100多种语言,还特别擅长处理那些"冷门"语言,简直是翻译界的"万语通"。
想象一下,未来我们可能会有这样的场景:你的AI助手能用20种语言和你聊天;你在网上冲浪时,跨语言信息检索系统帮你一秒破解语言壁垒;甚***在国际会议上,实时翻译系统让各国代表畅聊无阻,仿佛大家都说着同一种语言。
从马达加斯加的马尔加什语到格陵兰的格陵兰语,LLaMAX正在编织一张覆盖全球的语言网络。未来,这位AI语言大师不断突破自我,挑战更复杂的多语言任务,逐步缩小与专业翻译系统的差距。随着LLaMAX的持续进化,我们离实现真正的"世界语"梦想可能比想象中更近了!



发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。